This article is currently available in French. Version sous ce lien —> Flux de données ETL vs ESB : 5 points clés pour choisir la solution adéquate
ETL vs ESB: 5 Key Points to Choose the Right Solution
What is an ETL?
ETL, Extract Transform Load, is middleware that moves data from point A to point B at defined intervals. These three verbs summarize the three phases, or processes, of each data flow.
A first extraction phase, where data can come from any source—database, FTP, Amazon S3, Dropbox, Google Drive, Linux folder, etc.
Depending on the source, data can also be extracted in any format: SQL, JSON, XML, EDI, positional, Excel, and more.
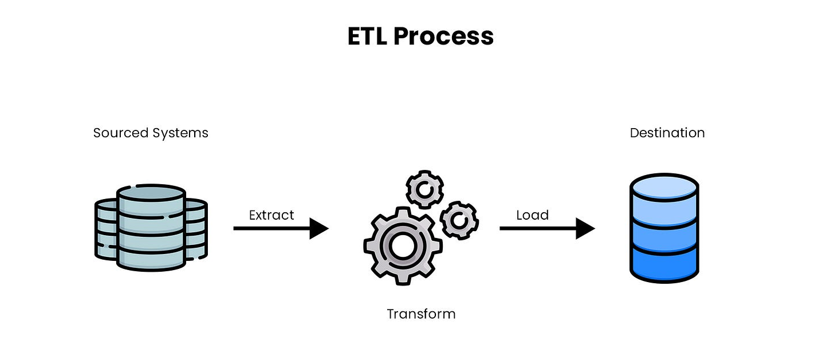
A second transformation phase applies business rules, cleans the data, filters out irrelevant data, etc.
A third integration phase loads the data into a target, just like extraction, in any format and source.
The advantage of ETL is its flexibility and ability to cover the most common use cases thanks to the diversity of input/output sources and formats.
The disadvantage of ETL is that it can become a “black box” that is difficult to maintain or evolve.
What is an ESB?
ESB, Enterprise Service Bus, allows applications within the same information system—which were not designed to work together—to communicate.
This issue is resolved by creating a bus that listens for and transmits data from application A to application B, and from application B to application A.
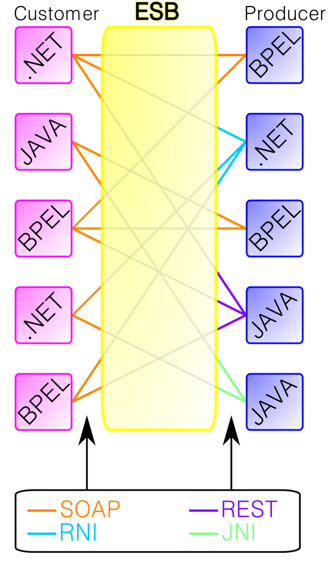
Moreover, if the client’s information system grows—due to an acquisition or the addition of a new tool for business teams, for example—the new application simply needs to be “connected” to the ESB to be integrated into the existing system.
The advantage is avoiding a complete overhaul of the information system with each new software or application integration.
The disadvantage is that applications must be able to exchange information in real time, typically using SOAP or REST formats.
How to Distinguish an ETL from an ESB?
Data Retrieval
The main difference between ETL and ESB concerns how data is retrieved.
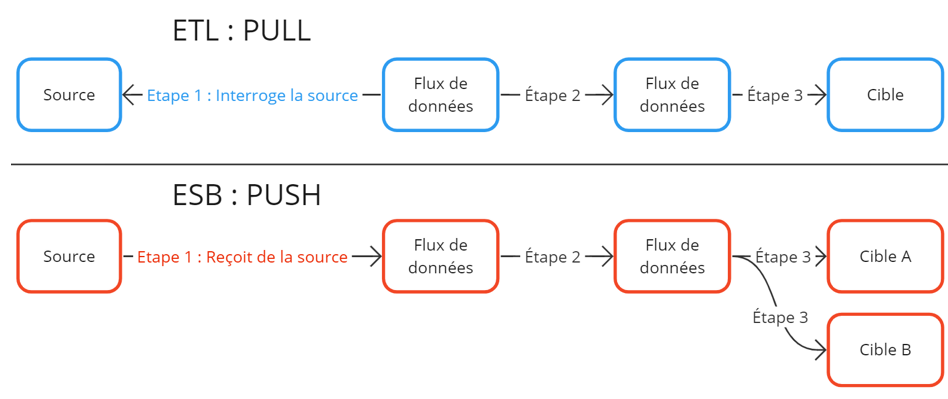
ETL works in “pull” mode: the data flow is scheduled, executed on demand, and fetches (=pulls) data from a defined source to perform the required work.
The ETL flow is active—it goes to get the data.
ESB works in “push” mode: the flow is “event-driven” and is triggered as soon as data is received from a source application.
Upon receipt, the bus distributes (=pushes) the received information to target applications via a publisher/subscriber system.
The ESB flow is passive—it transits the data.
Data Integration Delay
The second difference, linked to the first, is the data integration time.
ETL works on a scheduled basis: data is integrated when the scheduled flow completes its processing.
Depending on the trigger, the data is synchronized at the end of execution.
These triggers can be set up hourly, daily, at regular intervals, etc.
ESB, on the other hand, is event-driven. It receives data on the bus as soon as it is created or modified in the source application.
Once received on the bus, the data is sent to targets in real time after simple transformation steps and via a publisher/subscriber system. Unlike ETL, integration is real time.
Volume
The third difference, related to the second, concerns data volume.
ETL is designed to handle large volumes at scheduled times during the day, so at low intensity.
Example: a flow runs once a day, reads a table of ten thousand rows in a database.
In this case, it processes ten thousand rows and then stops.
Conversely, ESB is designed to handle small volumes but in real time, so at high intensity.
Example: the bus receives ten thousand independent data items throughout the day.
In this case, it processes ten thousand single-row transactions throughout the day, listening after each one (the ESB flow never stops).
Complexity
The fourth difference, linked to the third, concerns complexity.
Due to the volume, the ETL flow is more complex to set up because the code must be optimized to handle the load.
Add to this the “T” process in “ETL,” which involves more transformations.
An additional optimization layer is necessary to avoid degrading the performance of the server where the flow runs.
This may involve writing data to temporary files, for example, to increase the number of “sub-processes” within the flow, allowing data processing to be split into smaller parts.
The ESB flow, on the other hand, only receives data pushed from the source; its main purpose is to transit the data so applications remain synchronized.
The number and complexity of transformations in an ESB flow are lower compared to ETL.
Machine Resources and Parallelization
The fifth and final difference concerns the number of processes and resources consumed simultaneously.
ETL flows run one after another and stop when processing is complete.
This way of working requires more machine resources to launch, initialize the flow, and execute processing.
Combined with volume and the number of potential flows, server load can double (or more) if all flows run at once.
Unlike ESB, which is always listening, the flow is already instantiated and running, resources are ready to use, and incoming data arrives according to the load of the source applications (i.e., the application’s users).
This way, several requests can be processed simultaneously without impacting machine resources as much as ETL.
How to Choose? And Do We Really Have to Choose?
Before determining whether your need is for ETL or ESB, ask yourself these five questions:
-
Is my data need immediate?
- If yes, ESB; if not, ETL
-
Do I have complex transformations?
- If yes, ETL; if not, ESB
-
Is the volume of my data large?
- If yes, ETL; if not, ESB
-
Will I need to add more applications in the future?
- If yes, ESB; if not, ETL
-
Do I want to limit my budget?
- If yes, ETL; if not, ESB
“What if I want to take advantage of both ETL and ESB?”
The difference between ETL and ESB is becoming increasingly subtle; integrators are combining these two technologies to enjoy the benefits of both without the drawbacks, all within the same platform (see Talend API Cloud Services).
Thus, the question is no longer a functional choice but a purely technical one, depending on business needs, received data, required processing, logistical constraints, etc. The development team becomes responsible for these issues, while the company/executive vision is to choose the right application vendor (meeting needs, scalability, maintainability, and updates) and to require a generic receptacle to accommodate each evolution within this ETL + ESB platform.
You should never have to refactor everything or change the architecture with each new application. Technical expertise is therefore a crucial element to consider if you are planning for the long term.